转载请注明来源:http://iceflameworm.github.io/2019/08/12/chatterbot-github/
框架简介
Chatterbot是一个完全用python编写的基于文本检索/匹配的聊天机器人框架,它会从保存的对话语料中找出与输入句子最匹配的句子,并把匹配到的句子的下一句作为回答返回。本文主要对其工作流程,以及核心的训练器和逻辑适配器进行梳理,具体使用方法,请参考其文档。
框架地址:https://github.com/gunthercox/ChatterBot
文档地址:https://chatterbot.readthedocs.io/en/stable/
工作流程
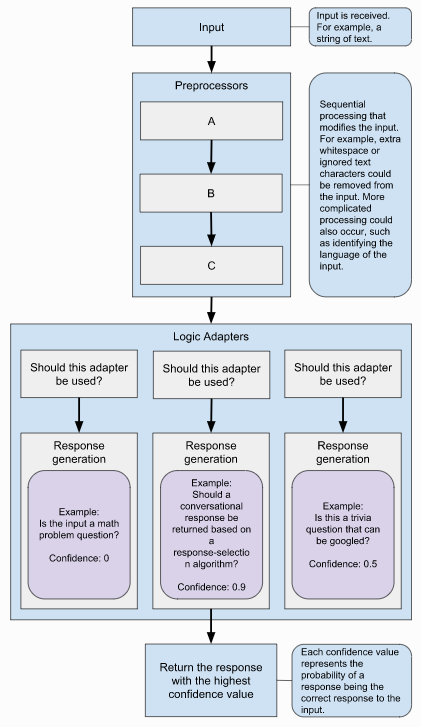
原文档中有两幅描述工作流程的示意图,一幅在文档首页,一幅在文档-逻辑适配器,个人认为后者描述的更全面、更恰当些,所以就以后者为准进行介绍。
从输入句子到输出响应回答,前后需要经历三大步:
- 预处理
- 生成答案
- 答案选择
具体流程请参考chatterbot.py。
预处理
与通常所讲的NLP预处理的目的基本一致,主要是文本进行一些标准还操作,比如去除连续的空格、删除特殊字符等等。Chatterbot框架自身实现了clean_whitespace, unescape_html和convert_to_ascii三种预处理功能。具体实现参见preprocessors.py
生成答案
一个Chatterbot实例可以绑定多个逻辑适配器,用于根据输入产生输出。
Chatterbot中没有独立的用于选择对话逻辑的意图识别模块,它将意图识别的功能放到了各个逻辑适配器中。接收到输入之后,Chatterbot会将其传递给各个逻辑适配器,由它们自己判断是否适合对输入的文本进行回答。如果逻辑适配器认为不能对输入进行回答,则会跳过,否则就输出回答,这样的话,有可能所有逻辑适配器都不输出回答,也有可能有多个逻辑适配器都给出了回答。具体请参考:ChatBot::generate_response方法。
从ChatBot::__init__和Chatbot::generate_response中的两端代码
1 | # __init__ |
可知,所有的逻辑适配器都共享一份保存的对话语料。倘若逻辑适配器内部不对数据进行选择的话,所有的逻辑适配器都将从所有的对话语料数据中查找最匹配的回答。这样的结果就是,每个逻辑适配器在相同的数据上用不同的匹配方法或指标产生回答,衡量每个回答confidence的标准并不一致,这会影响后续根据confidence进行答案选择。
答案选择
工作流程示意图显示,Chatterbot会从所有的逻辑适配器返回的回答中,选择confidence最大的,但是ChatBot::generate_response实现的是另外一种逻辑。在Chatbot::generate_response中,每个逻辑适配器输出的confidence并没有用到,它会统计每一个返回的回答出现的次数,如果有出现次数大于1次的,则会返回出现次数最多的回答,但是如果所有逻辑适配器返回的回答都只出现了一次,则会第一个逻辑适配器的答案,个人认为这种逻辑存在缺陷。以下是相关代码:
1 | # If multiple adapters agree on the same statement, |
训练器
刚开始的时候,以为这里的训练跟普通的训练是一样的,也就是通过数据+训练过程确定模型的参数。实际上,这里的训练过程不能算作真正的训练,有点跟KNN算法的训练过程差不多(KNN也没有真正意义上的训练过程),所谓的训练过程其实就是准备检索数据的过程。结合文档示例和 ListTrainer 可以看出Chatterbot框架中的训练过程实际上是怎样的。
文档中的示例
1 | from chatbot import chatbot |
ListTrainer
1 | class ListTrainer(Trainer): |
对话语料的保存并不是以文本对为单位的,而是把每一句话作为最基本的存储单元,语句之间的关系通过*in_response_to字段表示。如下述代码所示,Statement本身的text是用来回答in_response_to对应的previous_statement_text这句话的。
1 | Statement( |
逻辑适配器
逻辑适配器主要用于根据输入文本产生相应的回答。Chatterbot本身实现了一个BestMatch的逻辑适配器,它会从保存的对话语料中找出与输入文本最匹配的回答,其基本检索流程是:
- 根据某一相似度度量指标,从保存的对话语料中找到与输入文本最相似的文本 mtext。
- 遍历整个对话语料,找出所有可以用来回答m_text的文本。
从上述步骤可以看出, BestMatch找到回答需要遍历两次保存的对话语料,在实现方式上可能不是最优的。
具体流程参考 BestMatch::process。
在文本相似度度量上,Chatterbot本身已经实现了多种不同的方法:
- LevenshteinDistance-编辑距离
- JaccardSimilarity
- 使用Spacy计算的相似度
具体请参考 comparisons.py。